
Introduction
The Artificial Intelligence in the Creative Industries (AICI) project was conceptualised to address specific challenges in the early stages of visual storytelling development, particularly during concept exploration and ideation. Storyboarding serves as a critical blueprint for movies, games, and other visual media, yet the initial creative phase presents distinct bottlenecks: small teams often lack the specialised drawing skills to visualise and communicate their ideas quickly; iterating through multiple creative directions during concept development is time-intensive; and the need to generate numerous visual variations for exploration can slow down decision-making before production even begins.
Rather than replacing the creative process, the AICI project aimed to develop an AI-powered tool that functions as a starting point, helping creators rapidly explore visual concepts, bridge skill gaps in teams, and accelerate the early ideation phase, where speed and the quantity of iterations matter most. The tool was designed to assist creators in quickly generating diverse locations, consistent character representations, and dynamic camera positions, providing a foundation that artists can then refine, modify, and build upon with their own creative vision. By streamlining the exploration phase, the project seeks to give creators more time for the aspects of storyboarding that require human creativity, artistic judgment, and storytelling expertise.
Development work
Flux, a state-of-the-art image generation model, is a blend between transformer and diffusion models and can create high quality images with minimal prompting. Other models like stable diffusion require extensive prompt engineering via manually adding higher weights to certain words in the prompt to enforce it to adhere to long descriptive prompts. In contrast, flux models stayed true to descriptive prompts with minimal prompt engineering. Thus, flux was chosen as the image generation model for AICI to generate images for a storyboard where the prompts are picked from detailed descriptions in the script.
Locations
A simple black and white line art style was chosen to generate images. This was consistent with the genre of images usually used for a storyboard, which is often meant to be used as a quick prototype.

Location generated by flux in a line art style with the prompt “Park with lots of green trees. A park bench in the corner. Several people walking.”
Characters
Generating consistent characters in various poses proved to be a big technical challenge. Traditional AI models like controlnet openpose (used to generate images of a reference image in different poses) and IP-adapter (used to maintain image consistency of a reference image across different prompts) proved inefficient for ensuring consistency.
Consistency was finally achieved using simplistic sketch style images and prompt engineering. Once a reference character is generated, it can be manipulated to be in various poses by adjusting the prompt while using the same seed that was used to generate the reference image. This will preserve the characteristics so that it looks like the same character in a different pose.
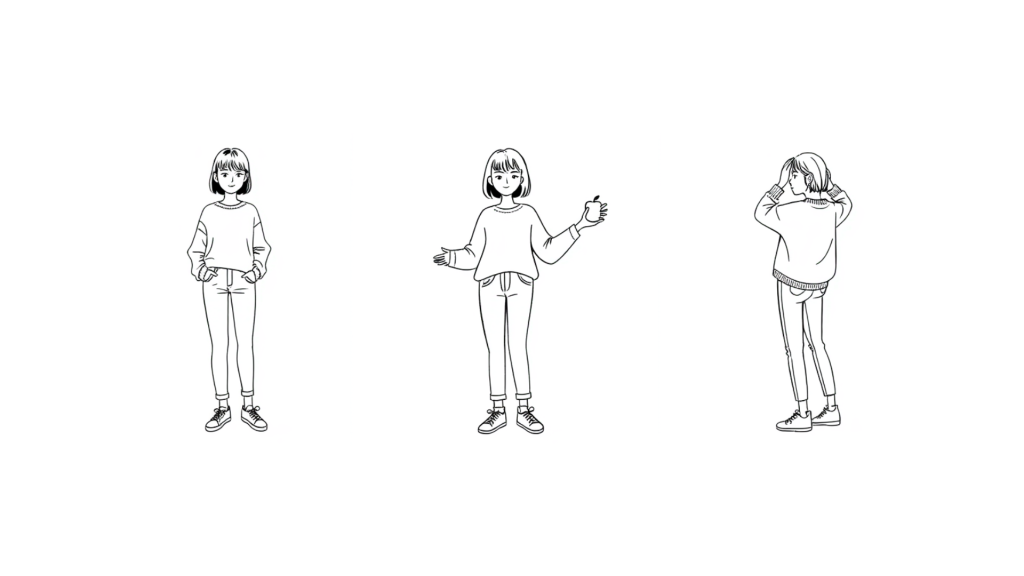
Consistent characters in various poses created via prompt engineering
Post-processing
Since image generation models are unable to create assets with transparent backgrounds, additional tools were built to separate characters from their backgrounds after generation. However, isolating a black-and-white character from a white background proved to be challenging. In order to resolve this, the characters were generated against a bright red background. This simple color choice made it much easier to accurately identify and extract just the character, providing a clean result.


Generated character with red background
Generated character after background removal
Superposition
Once the location and characters were generated, the next step in the process was superposing the characters seamlessly on the location. This process was split into 3 main parts:
- Coordinate-based pasting
- Object detection
- Natural language understanding
Coordinate-based pasting
Since both characters and locations were generated in the same artistic style, they naturally fit together without any complex editing. Simple placing of the characters into the generated locations at the right coordinates, and programmatically resizing the character to blend with the location ensured they looked like they belonged there from the start.
Object detection
The next step was to automate the placement process. This was achieved with the help of Microsoft’s Kosmos 2 model, which can identify and locate objects in images. This model scans the generated scenes and identifies what objects are present, where they’re positioned, and how much space they take up. These objects were then used as reference points for placing characters. When the system finds an object that matches what the user described in their prompt, like ‘bench’ or ‘tree’, it automatically positions the character in that spot.
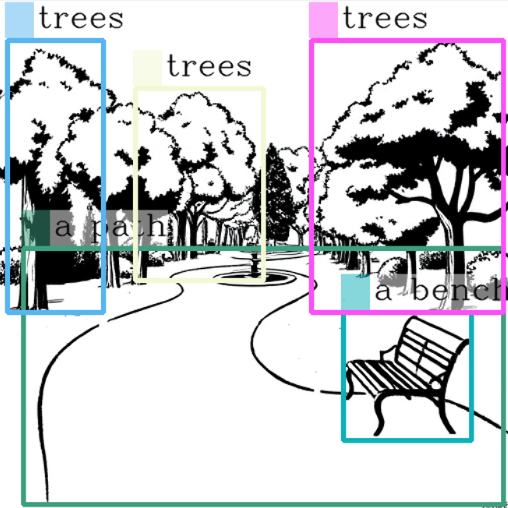
Object detection output on generated location
Natural language understanding
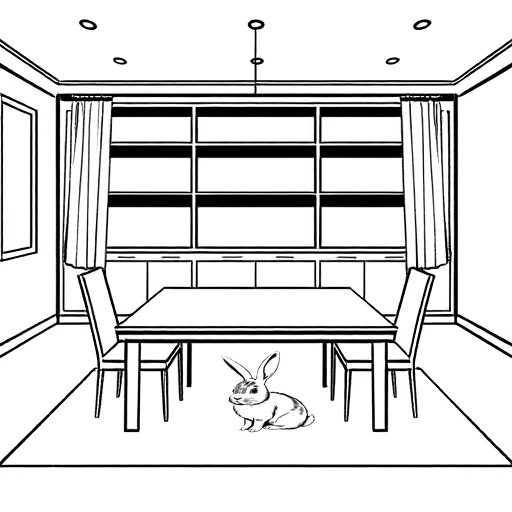
This approach provided partial automation of the character placement process, significantly reducing manual work. However, additional adjustments were needed to handle complex scenes and varied user prompts. Simply placing characters directly on top of matched objects didn’t always produce the best results. To address this, a natural language processing model was fine-tuned to understand the subject → preposition → object relationships in user prompts. The system was trained to recognize 18 different prepositions – 7 primary and 11 secondary ones. For each main preposition, specific placement rules were defined to control how characters would be positioned relative to objects. These rules managed spacing, overlap, and alignment to ensure placements looked natural and coherent. Each preposition came with default settings that determined whether characters would overlap with objects or maintain a gap from them. Users could also manually adjust these default values, providing flexibility for situations where the automatic positioning didn’t quite achieve the desired result.

Result with prompt: “The boy is sitting next to the campfire.”
Result with prompt: “The bunny is hiding from the storm under the table.”
Camera positions
Once the characters were superposed on the location, it was necessary to offer a way to manipulate camera positions in order to build a shot. Outpainting is a technique where generative AI is used to extend a reference image outward by adding new visual elements outside the original frame (e.g. by extending the scenery) in a way that harmonizes with the existing image. Flux fill is an AI model that supports outpainting using the flux text-to-image model.
Flux fill expects a reference image as the input along with a mask where additional visual elements need to be generated. The new elements are generated by keeping the seed of the original image consistent. This ensures the newly generated aspects of the image are consistent with the original image and blends in cohesively.
AICI supports generating a wide, extra wide, and Dutch tilt shots from a base shot. Maneuvering camera angles to create birds’ eye view, worms’ eye view etc. required changing the angle of the reference image and will require text-to-3D image generation models. These were beyond the scope of this project and is not currently supported in the tool.

Reference image (left) and the generated wide shot (centre) and extra wide shot (right) using outpainting

Reference image (left) with the generated Dutch tilt shots (center and right) using outpainting
Challenges and limitations
Throughout the development process, numerous creative solutions were discovered alongside limitations within the current technology. Working within a 2D space meant that certain complex camera perspectives, such as bird’s eye views or extreme high and low angles, remained out of scope. The deliberate choice to work with sketch-style images, while artistically rewarding, introduced its own constraints due to the limited availability of open-source training data for refining these particular visual styles. Achieving complex poses for a character may require multiple attempts with different prompts and seeds, potentially leading to a degraded user experience.
The current implementation of superposing the characters on the location cannot place characters inside visual elements that have already been superposed in a scene. For instance, if a character is envisioned sitting in a car, these contextual elements need to be incorporated during the initial character generation phase rather than superposed afterward.
Conclusion
While the prototype operates within certain technical boundaries, it successfully achieves its core objective: providing creators with a rapid exploration tool for the earliest stages of visual storytelling. The lessons learned throughout this development process offer valuable insights for the continued evolution of AI-assisted creative tools.