
“What if AI could imagine the future of a world instead of just generating text?”
What are World Models?
World models aim to predict what happens next by learning how environments evolve over time. Unlike traditional AI systems focused on language, these models move toward visual and spatial reasoning, enabling machines to simulate dynamic worlds.
Traditional video models generate sequences “like a movie”. In contrast, a world model has to stay consistent when you change direction, go back, or trigger an event. By simulating dynamic 3D environments, these models empower agents to perceive and interact with complex surroundings, opening up new possibilities for robotics and game development.
A world model is essentially an AI system that learns an internal representation of an environment and predicts how that environment will change over time. Instead of only responding to current inputs, the model can simulate possible future scenarios.
This concept is inspired by how humans reason about the world. When people imagine what might happen after taking a particular action, they are effectively using an internal mental model of the world.
In machine learning, world models often work by:
- Observing data from an environment, such as images, videos, actions.
- Learning a compressed internal representation of the environment
- Predicting how the environment evolves over time based on the representation.
What are the differences of video-based world generation methods and 3D based world methods?
Video based methods leverage the inherent world knowledge of video diffusion models to understand the temporal and spatial relationships of generated world. The rich training data available for video models enables them to capture complex real-world dynamics for generating visually compelling results across different scenarios. Some works further incorporate 3D constraints such as camera trajectories or explicit 3D scene point clouds to spatially control the generated video sequences and produce plausibly 3D consistent video worlds.
However, video-based approaches face several limitations that constrain their practical performance. First, they inherently lack true 3D consistency due to their underlying 2D frame-based representation. This leads to temporal inconsistencies, particularly when generating long-range video scenes. Second, the rendering costs of video-based methods are prohibitive, as each frame should be generated sequentially. Third, the frame-based video format is fundamentally incompatible with existing computer graphics pipelines, making it hard to be incorporated into game engines, VR applications, and other interactive systems.
In contrast, 3D-based world generation methods directly model geometric structures and offer compatibility with current computer graphics pipelines. These approaches provide inherent 3D consistency with efficient real time rendering.
Experimental Developments
Most world models are still in the research phase. With the exception of Marble, these systems are primarily open-source research projects rather than production-ready tools. As a result, they are not yet available as fully developed APIs and require experimentation and technical setup to use.
Marble
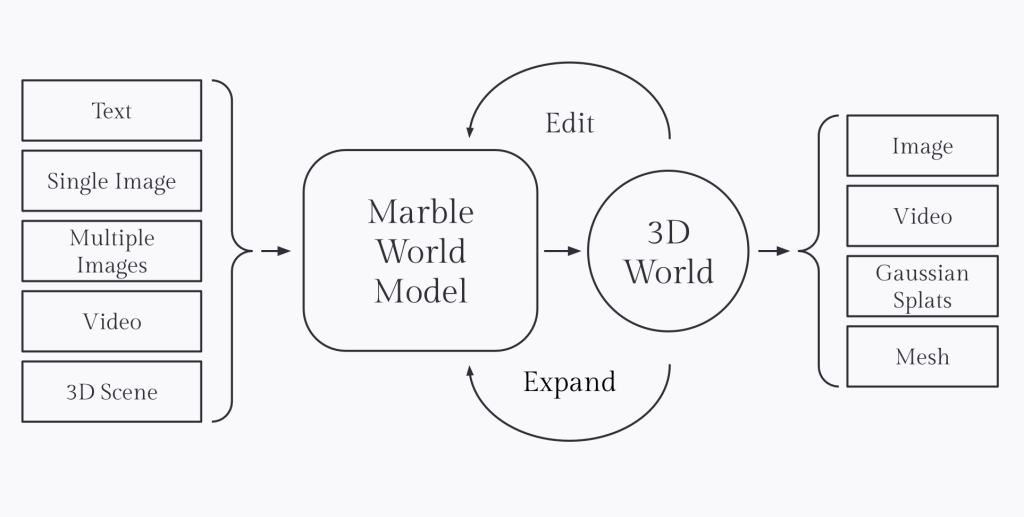
Marble is a massively multimodal world model that can generate 3D environments from text, images, video, or coarse 3D layouts, while also allowing users to interactively edit, expand, and combine worlds with fine‑grained control. It is designed as a spatially intelligent system: it lifts whatever signals are available into a coherent 3D world, continuously refines its internal representation as new information arrives, and supports interactive editing in both 2D and 3D. Beyond one‑shot generation, Marble offers AI‑native world editing, a “Chisel” mode for sculpting structure with coarse geometry while independently controlling style via text, and tools to grow and compose multiple scenes into large, traversable worlds. Generated environments can be exported as high‑fidelity Gaussian splats, collider or high‑quality meshes for downstream pipelines, or rendered as videos with precise camera control, making Marble a strong backbone world model for gaming, VFX, design, and robotics simulation workflows.
LingBot-World

LingBot-World is an open‑source world model developed by Robbyant (Ant Group) that transforms video generation into real‑time interactive simulation, generating high‑fidelity, controllable 3D environments at 16 FPS for embodied AI, autonomous driving, and gaming.
It employs a three-stage training pipeline: pre-training on diverse video data establishes a strong foundation; middle-training injects world knowledge and action controllability, enabling long-term dynamics with consistent interactive logic; and post-training adapts the architecture for real-time interaction using causal attention and few-step distillation for low latency and strict causality.
This model supports promptable world events (e.g., weather changes, dynamic objects), zero‑shot generalization from single images, agent policy training, and 3D reconstruction from geometrically consistent outputs.
HunyuanWorld 1.0
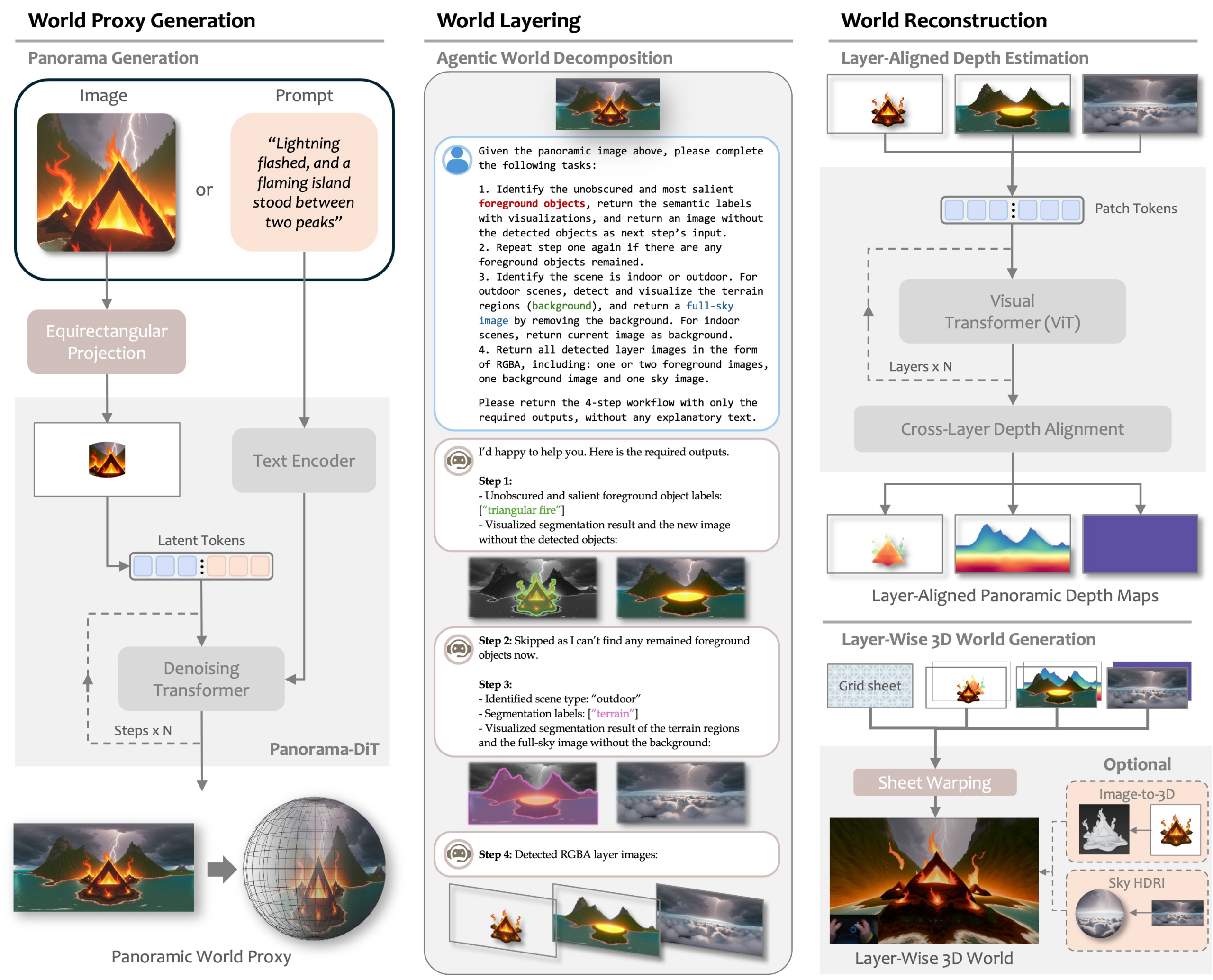
HunyuanWorld 1.0 generates interactive environments through several key design components that enable the creation and exploration of coherent 3D worlds. First, it uses panoramic world image generation (Panorama-DiT), which acts as a unified world representation for both text-to-world and image-to-world generation. This panoramic view serves as the foundational proxy of the environment.
Next, the system applies agentic world layering, automatically decomposing complex scenes into semanticallymeaningful layers. This process separates objects and structural elements within the scene, preparing them for more accurate 3D reconstruction and enabling disentangled object modeling.
Following this step, HunyuanWorld performs layer-wise 3D reconstruction, estimating aligned panoramic depth maps to generate a mesh-based 3D world across all extracted layers. The resulting hierarchical world mesh representation explicitly separates objects while maintaining efficient memory usage and rendering performance.
HY-World 1.5
HunyuanWorld 1.0 generates immersive, traversable 3D worlds but lacks real-time interaction. HY-World 1.5 bridges this gap with WorldPlay, a streaming video diffusion model enabling real-time, interactive world modeling.This model draws power from 4 key designs:
- Dual Action Representation used for robust action control in response to the user’s keyboard and mouse inputs.
- Reconstituted Context Memory enforces long term consistency with dynamically rebuilding context from the past frames and use temporal reframing to keep geometrically important but long-past frames accessible, effectively alleviating memory attenuation.
- A novel Reinforcement Learning post training framework, WorldCompass designed to directly improve the action following and the visualization quality of the video model.
- Context Forcing, a novel distillation method designed for memory aware models
This model shows strong generalization across diverse scenes, supporting first-person and third-person perspectives in both real-world and stylized environments, enabling versatile applications such as 3D reconstruction, promptable events, and infinite world extension.
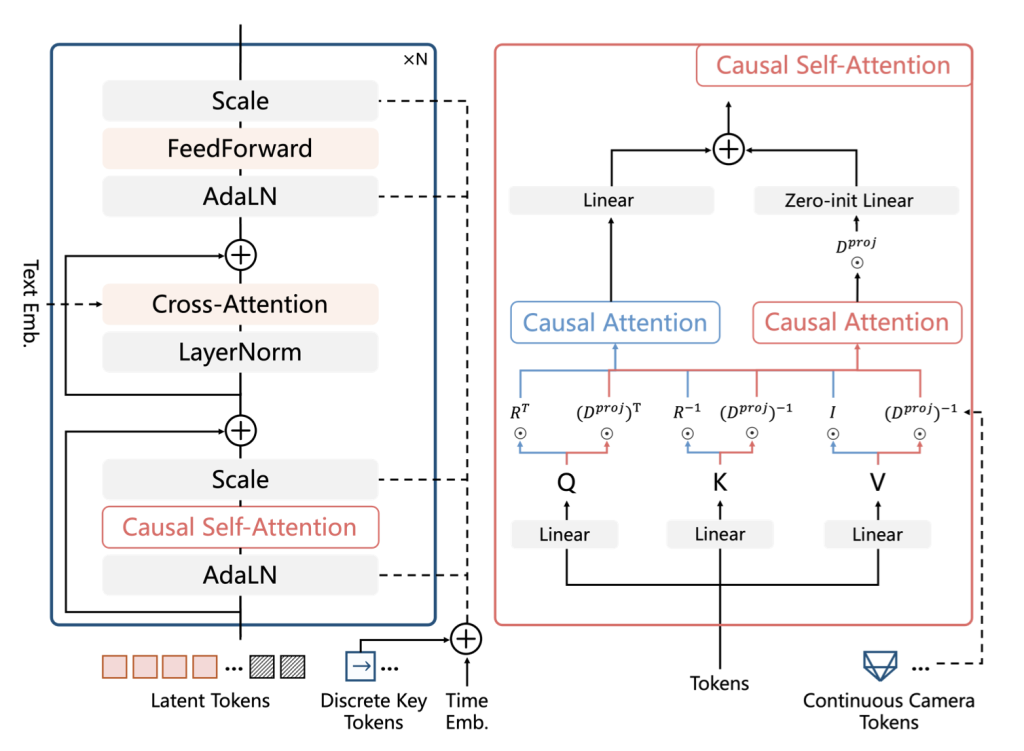
WorldGen
Properties
WorldGen enables automatic creation of large-scale, interactive worlds directly from text and image prompts. This approach transforms natural language descriptions into traversable, fully textured environments that can be immediately explored or edited within standard game engines. This model is built on a combination of procedural reasoning, diffusion-based 3D generation, and object-aware scene decomposition. The result is geometrically consistent, visually rich, and render efficient 3D worlds for gaming simulation and immersive social environments.
Limitations:
Still in the resarch phase and not publicly available for developers. However, the content generated by WorldGen is compatible with standard game engines including Unity and Unreal without the need for additional conversions or rendering pipelines.
Matrix 3D
This model utilized panoramic representation to enable wide-coverage, omnidirectional, explorable 3D world generation.
To convert the generated panoramic image into a 3D environment, the system uses two different reconstruction approaches:
- Feed-forward panorama reconstruction model designed for rapid 3D scene reconstruction from the generated panoramic image.
- Optimization-based reconstruction pipeline designed to produce more accurate and detailed 3D scene reconstructions.
Model Evaluation Table
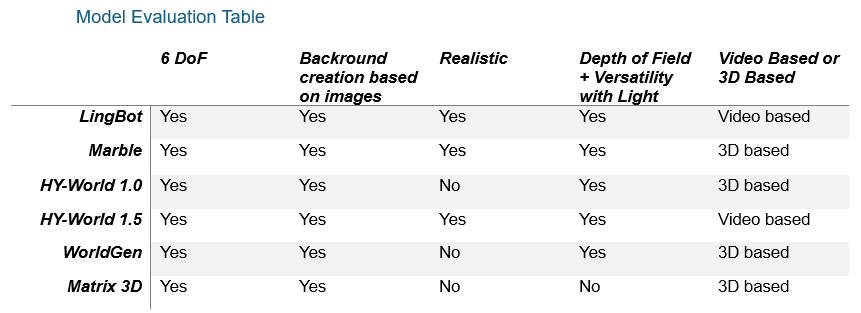
Conclusion:
The models discussed were evaluated based on five key criteria. Among them, Marble stands out as the strongest overall option, capable of generating high-quality, realistic 3D environments without requiring local implementation. For users looking for 3D-based models that can run locally, WorldGen and HunyuanWorld 1.0 are strong alternatives. If you are specifically interested in video-based world models,HY-World 1.5 produces some of the most visually impressive results. However, it is important to note that world models require significant computational resources, and running inference on them is often not feasible on consumer-level GPUs.